들어가며
현재 회사 프로덕트는 AWS ECR과 EC2를 통해 애플리케이션을 배포하고 있는데, 최근 CloudFront와 S3를 활용한 배포 방식을 경험하면서 이 구조가 가져다주는 획기적인 성능 향상을 직접 확인할 수 있었다. 그동안 다양한 최적화 기법을 시도해왔는데, 리소스 자체가 최적화되어 있지 않으면 성능 개선에 한계가 있다는 것을 알 수 있었기에 회사의 프로덕트 배포 아키텍처를 CloudFront 기반으로 전환하는 것을 검토하게 되었다.
배포 방식 전환을 고려하게 된 또 다른 계기가 있다. 최근 프로덕트 운영 중 재배포 시마다 동적 import 모듈을 찾을 수 없다는 에러가 지속적으로 발생했다.

특히 웹뷰 환경에서는 사용자가 배포 이전 버전의 페이지를 계속 참조하고 있어, 더 이상 존재하지 않는 모듈을 요청하는 경우가 빈번했다. 따라서 앱을 다시 재접속해야 하는 불편함이 계속해서 뒤따랐다. 현재는 해당 에러 발생 시 페이지 새로고침으로 임시 대응하고 있다. 하지만 이는 새로 고침을 하면서 발생하는 화면 깜빡임과 상태 초기화를 동반하여 예기치 않은 부작용을 초래할 수 있어 우려가 되었다.
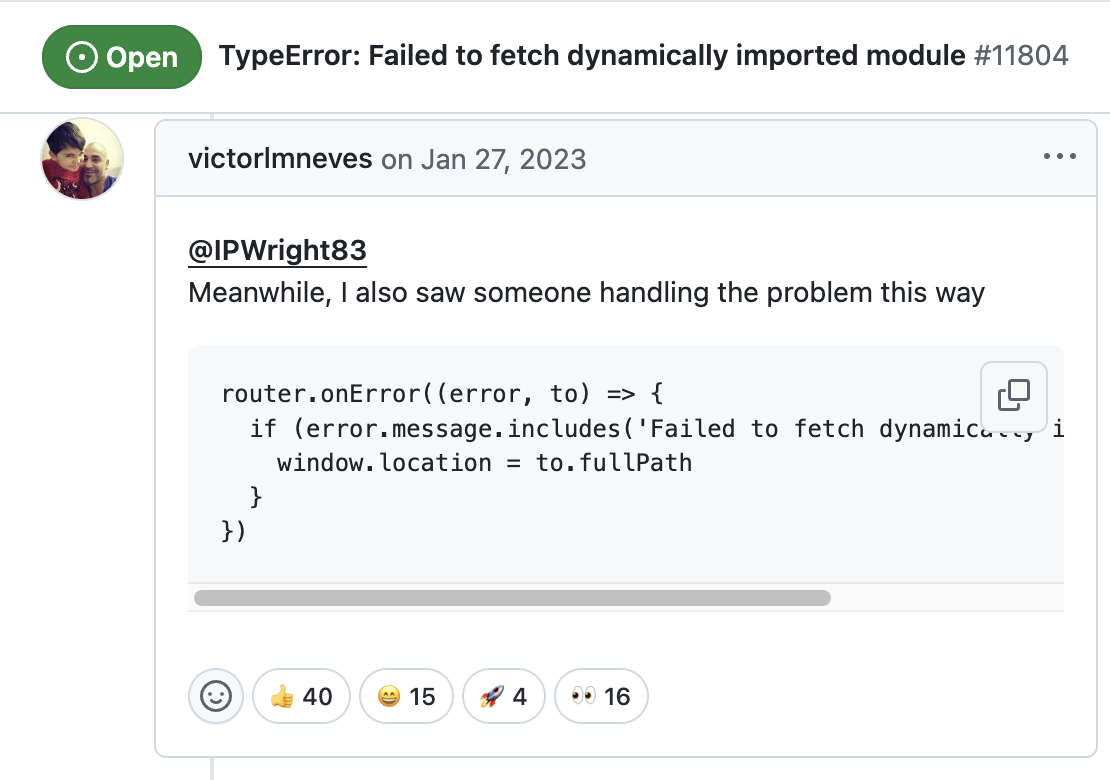
이러한 문제가 발생하는 근본적인 원인은 재배포 시 빌드 과정에서 모듈의 해시값이 변경되기 때문이다. 빌드 시 모듈은 A-Dnds3.js와 같이 파일명에 해시값을 포함한다. 동적 import의 경우 해시값에 해당하는 모듈을 필요한 시점에 요청하지만 재배포 후에는 해시값이 갱신되어 배포 이전 해시값을 가진 모듈이 서버에서 제거되기 때문에 더 이상 접근이 불가능해진다. 그래서 동적 import 중인 모듈을 찾을 수 없다는 에러가 발생하게 되는 것이다.
이에 대한 해결책으로 CloudFront와 S3를 활용한 배포 방식을 도입하여 재배포 후에도 일정 기간 동안 이전 버전의 모듈을 유지하는 방안을 고려하고 있다. 이를 통해 크리티컬한 상황에서만 선별적으로 새로고침을 유도해서 최신 버전의 모듈을 불러오는 게 좋을 것 같다 생각했다. 따라서 관련 기술을 익히기 위해 이렇게 기술 조사를 하게 되었다.
Amazon S3 (Simple Storage Service)

S3는 AWS에서 제공하는 클라우드 기반 객체 스토리지 서비스로 클라우드와 유사하다고 생각하면 된다. 각 객체는 파일 데이터와 함께 생성 날짜, 크기, 이름 등의 메타데이터를 포함한다.
버킷
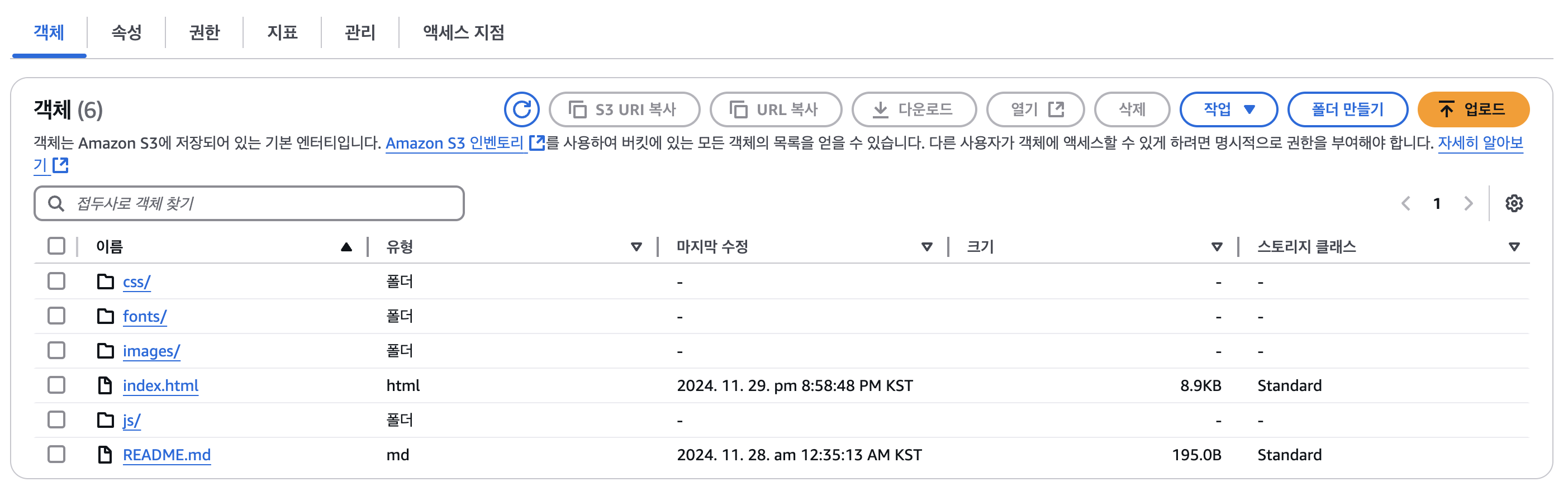 S3에 데이터를 업로드 하기 위해서는 버킷이라는 객체들을 저장하는 컨테이너를 생성해야 한다. 버킷을 생성할 때는 region을 설정하는데 지연 시간을 줄이고, 비용을 최소화하고, 규제 요건을 해결하려면 지리적으로 가까운 AWS 리전을 선택하는 게 좋다. 생성된 객체들은 다음과 같은 주소를 통해 접근도 가능하다.
S3에 데이터를 업로드 하기 위해서는 버킷이라는 객체들을 저장하는 컨테이너를 생성해야 한다. 버킷을 생성할 때는 region을 설정하는데 지연 시간을 줄이고, 비용을 최소화하고, 규제 요건을 해결하려면 지리적으로 가까운 AWS 리전을 선택하는 게 좋다. 생성된 객체들은 다음과 같은 주소를 통해 접근도 가능하다.
https://{bucketName}.s3.{region}.amazonaws.com/{key}
https://amzn-s3-demo-bucket.s3.us-west-2.amazonaws.com/photos/puppy.jpg버전 관리
버전 관리를 통해서 모든 버전의 객체들을 보존, 검색, 복원을 할 수 있기 때문에 예상치 못한 장애로부터 쉽게 복구가 가능하다. 객체를 삭제할 때 S3는 영구적으로 제거하는 게 아니라 삭제 마커를 적용하는데 이 때 삭제 마커가 적용된 객체가 현재 버전이 되고, 객체를 덮어쓸 때도 객체의 새 버전이 생성되기 때문에 복원을 쉽게 할 수 있다. 기본적으로 버킷의 버전관리는 사용 중지 되어 있기 때문에 사용 설정을 따로 해주어야 한다.
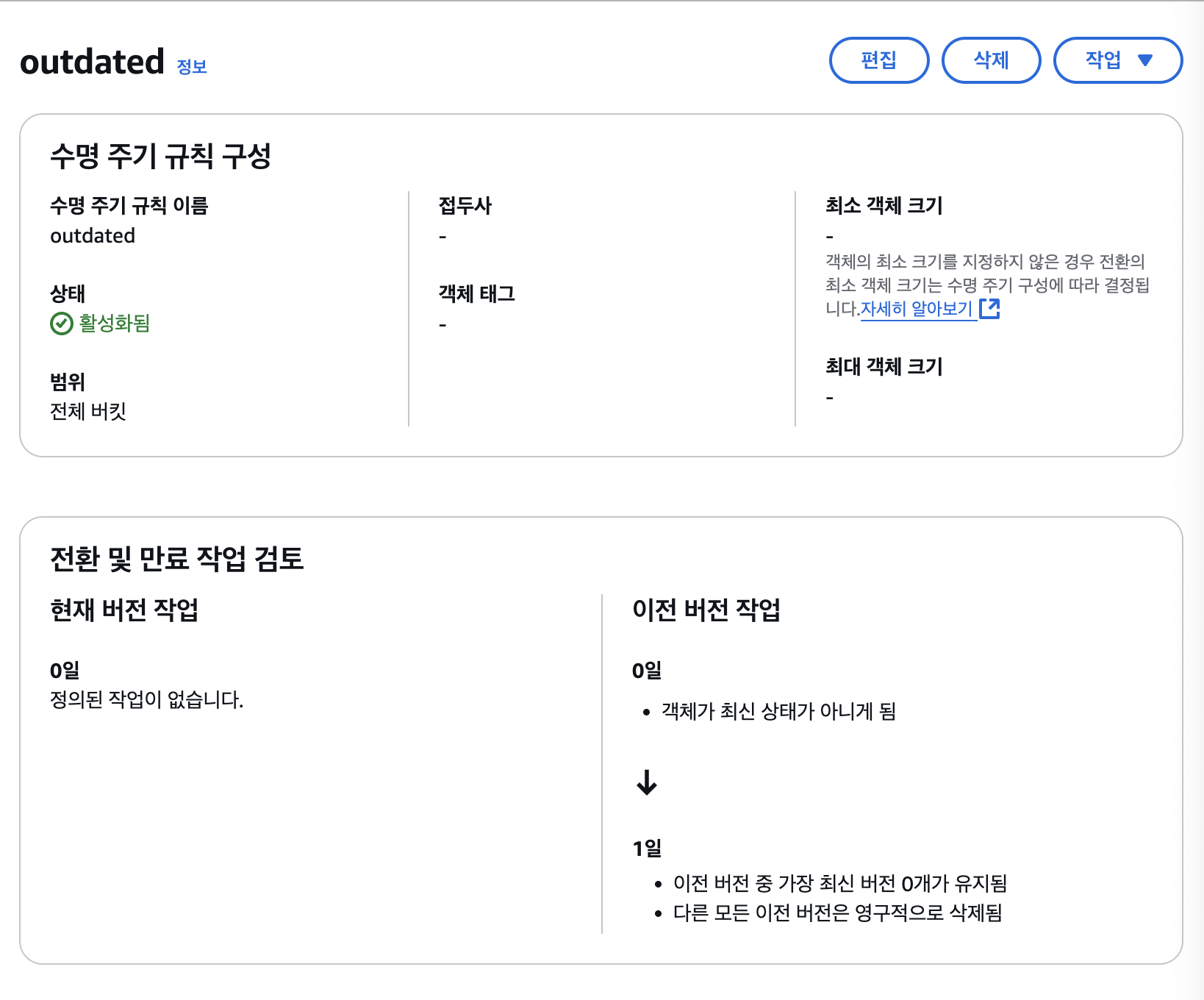
수명 주기 관리
이는 내가 S3를 도입하면서 달성하고자 했던 목표를 이루게 해준다. 모듈에 대한 수명 주기를 관리할 수 있기 때문에 재배포 후 얼마나 모듈을 유지할지에 대한 설정을 적용할 수 있다. 버킷의 수명 주기는 transition과 expiration 두 가지 방식으로 관리할 수 있다.
transition
transition은 스토리지 클래스를 전환하는 것이다. 객체에 대해 사용 시나리오나 요구 성능에 따라 스토리지 클래스를 선택할 수 있는데 적절한 스토리지 클래스를 선택하면 객체의 스토리지 비용, 성능, 가용성을 최적화 할 수 있다.
- S3 Standard: 기본 스토리지 클래스. 객체 업로드 시 따로 지정하지 않으면 Standard로 클래스를 할당한다.
- S3 Express One Zone: 빠른 로드를 하기 위해서는 해당 클래스를 사용하는 게 좋다. 고성능을 제공하기 때문에 Standard보다 데이터 엑세스 속도가 10배가 빠르다.
- Reduced Redundancy Storage: 중요하지 않고, 자주 사용되지 않는 데이터용 클래스다. 그러나 이를 대신하여 Standard를 사용하는 게 비용상 더 효율적이기 때문에 AWS에서 추천하지 않는다.
expiration
객체의 만료 시점을 정의할 수 있는데 S3는 버킷의 상태에 따라 만료 처리 작업을 한다.
- 버전이 지정되지 않은 버킷: 제거할 객체를 대기열에 넣고 비동기적으로 제거하여 객체를 영구적으로 제거함.
- 버전이 지정된 버킷: 객체의 버전이 삭제 마커가 아니라면 삭제 마커를 적용함. 휴지통에 들어가있는 것과 같다.
CloudFront
빠른 컨텐츠 서빙
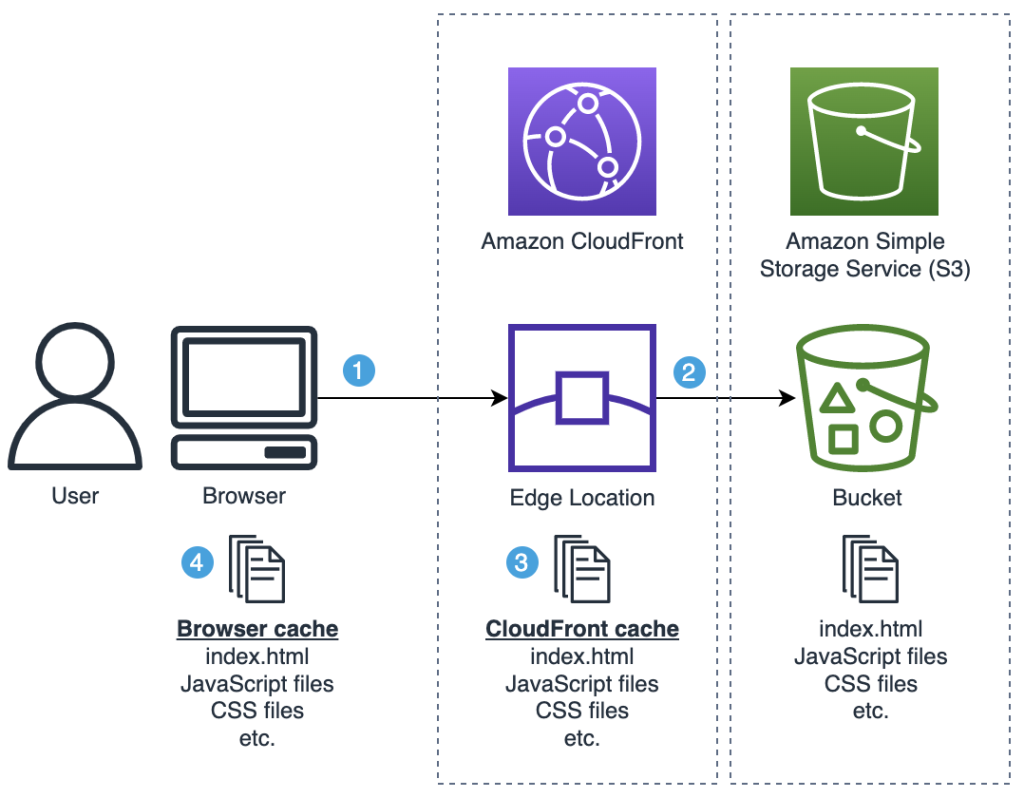
CloudFront는 AWS에서 제공하는 CDN(Content Delivery Network) 서비스인데, 이를 통해서 사용자는 빠르게 컨텐츠를 받아볼 수가 있게 된다. 어떻게 가능하냐면 사용자가 웹 사이트에 접근하면 DNS는 사용자와 위치적으로 가장 가까운 CDN인 CloudFront 엣지 로케이션으로 라우팅 하는데, 여기서 엣지 로케이션이란 전 세계 지역에 분산되어 배치된 서버를 말한다. 이 엣지 로케이션은 요청 받은 컨텐츠가 이미 캐싱되어 있다면 빠르게 컨텐츠를 사용자에게 전달할 수 있다. 엣지 로케이션에 컨텐츠가 캐싱되어 있지 않을 경우에는 원본 서버(S3)에서 컨텐츠를 가져오는데 이 때 다음 요청을 위해 캐싱 작업을 해둔다. 이런 방식으로 콘텐츠 응답시간을 줄일 수 있고, 엣지 로케이션에서 콘텐츠를 서빙하기 때문에 S3의 서버 부담도 줄일 수 있다.

캐싱을 얼마나 오래 해둘 건지 TTL(Time To Live)을 설정할 수도 있다. 만료되기 전까지는 엣지 로케이션에서 파일을 제공하는데 만료가 된 후에는 원본 서버에 최신 버전의 파일이 있는지 확인한다. 파일은 만료가 되었는데 원본 서버에 업데이트된 최신 버전의 파일이 없으면 304 상태코드를 반환하고, 있다면 상태코드 200와 함께 최신 파일을 반환한다. 동적 컨텐츠라면 캐시 기간을 단축해서 컨텐츠의 최신 상태를 보장할 수도 있다.
압축
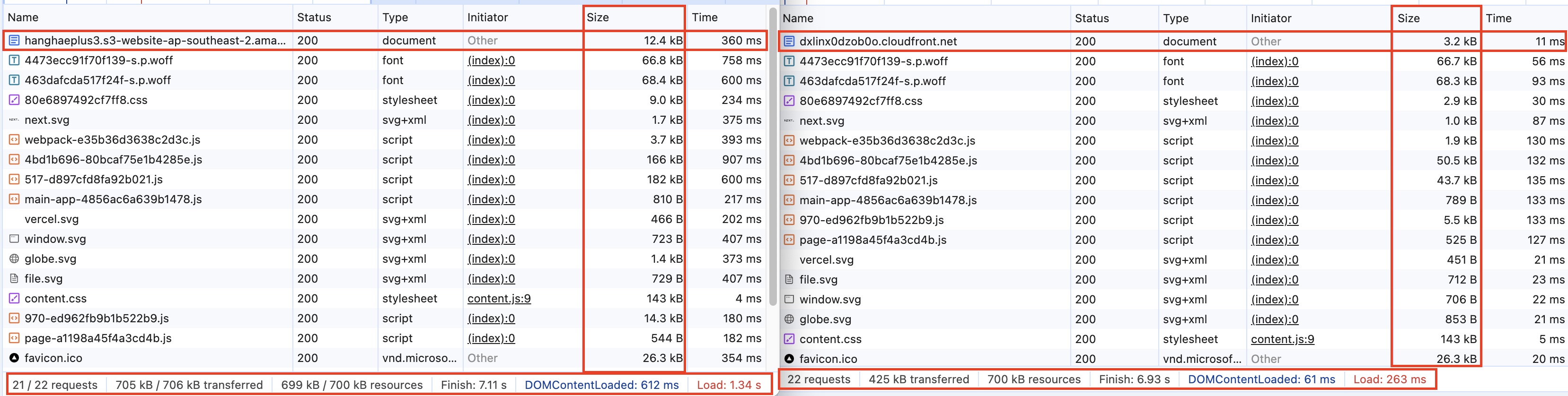 CloudFront 도입 전(S3만으로 컨텐츠를 서빙 받았을 때)과 후인데 로드 시간과 파일 용량이 많이 줄었다는 걸 확인할 수 있다. 로드 시간은 1.34s에서 263ms로 약 80%의 속도 향상이 되었고, 파일 크기도 30~70% 정도 압축되었다. 이는 CloudFront가 특정 유형의 파일을 자동으로 압축하기 때문이다.
CloudFront 도입 전(S3만으로 컨텐츠를 서빙 받았을 때)과 후인데 로드 시간과 파일 용량이 많이 줄었다는 걸 확인할 수 있다. 로드 시간은 1.34s에서 263ms로 약 80%의 속도 향상이 되었고, 파일 크기도 30~70% 정도 압축되었다. 이는 CloudFront가 특정 유형의 파일을 자동으로 압축하기 때문이다.

Gzip나 Brotli라는 압축 형식을 사용해서 객체를 압축해주는데 사용자의 브라우저에서 두 형식 모두 지원한다면 기본적으로 Brotli로 압축을 한다. Chrome과 Firefox는 HTTPS 요청일 경우에만 Brotli를 지원한다. 원본 크기의 1/4 이하까지도 용량이 줄어들 수 있다.
배포 파이프라인 구성
현재 회사에서 Bitbucket을 사용하고 있기 때문에 어떤 방식으로 Pipelines를 구성해야하는지 알아보았다. 내가 임시로 만든 파이프라인은 크게 두 단계로 구성되어 있다.
- Build 단계:
- Node.js 캐시를 사용하여 빌드 성능을 향상
- npm ci로 의존성 설치 (npm install보다 더 엄격하고 안전한 설치)
- npm run build로 프로젝트 빌드
- build 폴더의 결과물을 아티팩트로 저장
- Deploy 단계:
- AWS S3에 배포:
- atlassian/aws-s3-deploy 파이프 사용
- AWS 인증 정보는 환경 변수로 삽입
- build 폴더의 내용을 지정된 S3 버킷에 업로드
- —delete 옵션으로 기존 파일 정리
- CloudFront 캐시 무효화:
- atlassian/aws-cloudfront-invalidate 파이프 사용
- 배포 후 CloudFront의 캐시를 갱신하여 최신 내용이 사용자에게 전달되도록 함
여기서 aws-s3-deploy라는 pipe는 Atlassian에서 제공하는 Bitbucket Pipelines용 파이프로서 AWS S3 버킷에 파일을 쉽게 업로드를 수행할 수 있게 한다. AWS CLI를 자동으로 설치, 설정을 해주기 때문에 따로 해당 과정에 대한 스크립트를 작성하지 않아도 된다. aws-cloudfront-invalidate는 CloudFront의 캐시를 무효화하는 Bitbucket의 Pipelines 파이프로서 CloudFront 캐시를 무효화하여 새로 배포된 파일들이 즉시 반영되도록 도와준다.
이렇게 하면 prod라는 브랜치에 코드가 푸시될 때마다 이 파이프라인이 자동으로 실행된다. 웹 애플리케이션을 빌드하고 빌드된 파일들을 AWS S3에 배포한 후, CloudFront를 통해 콘텐츠를 배포하는 과정을 자동화해준다.
pipelines:
branches:
prod:
- step:
name: Build
caches:
- node
script:
- npm ci
- npm run build
artifacts:
- build/**
- step:
name: Deploy
script:
- pipe: atlassian/aws-s3-deploy:1.1.0
variables:
AWS_ACCESS_KEY_ID: $AWS_ACCESS_KEY_ID # AWS 접근 키
AWS_SECRET_ACCESS_KEY: $AWS_SECRET_ACCESS_KEY # AWS 시크릿 키
AWS_DEFAULT_REGION: $AWS_DEFAULT_REGION # AWS 리전
S3_BUCKET: $S3_BUCKET_NAME # 대상 S3 버킷 이름
LOCAL_PATH: 'build' # 업로드할 로컬 파일/폴더 경로
EXTRA_ARGS: '--delete' # 기존 S3 버킷의 파일들을 삭제하고 새로운 파일들로 교체
- pipe: atlassian/aws-cloudfront-invalidate:0.6.0
variables:
AWS_ACCESS_KEY_ID: $AWS_ACCESS_KEY_ID # AWS 접근 키
AWS_SECRET_ACCESS_KEY: $AWS_SECRET_ACCESS_KEY # AWS 시크릿 키
AWS_DEFAULT_REGION: $AWS_DEFAULT_REGION # AWS 리전
DISTRIBUTION_ID: $CLOUDFRONT_DISTRIBUTION_ID # CloudFront 배포 ID참고 문서